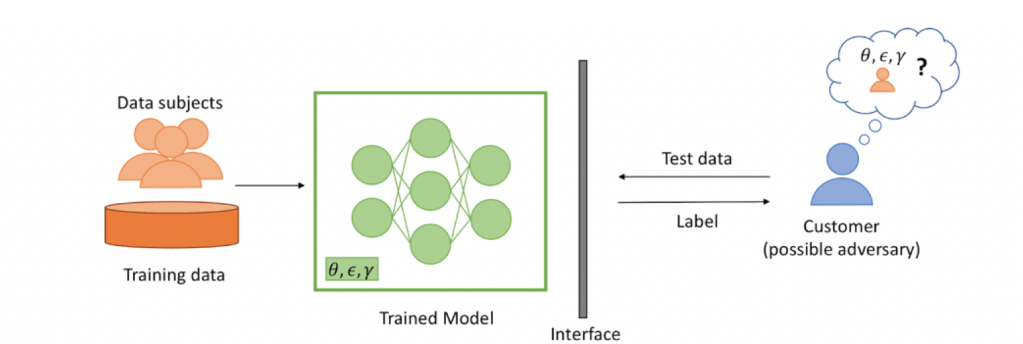
Data analysis methods using machine learning (ML) can unlock valuable insights for improving revenue or quality-of-service from, potentially proprietary, private datasets. Having large high-quality datasets improves the quality of the trained ML models in terms of the accuracy of predictions on new, potentially untested data. The subsequent improvements in quality can motivate multiple data owners to share and merge their datasets in order to create larger training datasets. For instance, financial institutes may wish to merge their transaction or lending datasets to improve the quality of trained ML models for fraud detection or computing interest rates. However, government regulations (e.g., the roll-out of the General Data Protection Regulation in EU, the California Consumer Privacy Act or the development of the Data Sharing and Release Bill in Australia) increasingly prohibit sharing customer’s data without consent. This motivates the need to conciliate the tension between quality improvement of trained ML models and the privacy concerns for data sharing. Therefore, this is a need for privacy-preserving machine learning.
- N. Wu, F. Farokhi, D. Smith, M. A. Kaafar, “The Value of Collaboration in Convex Machine Learning with Differential Privacy,” in Proceedings of the 41st IEEE Symposium on Security and Privacy, May 18-20, 2020, San Francisco, CA, USA.
- F.Farokhi,“Privacy-Preserving Public Release of Datasets for Support Vector Machine Classification,” IEEE Transactions on Big Data, 2020.
- F. Farokhi, M. A. Kaafar, “Modelling and Quantifying Membership Information Leakage in Machine Learning,” Submitted.
- F. Farokhi, M. A. Kaafar, “Predicting Performance of Asynchronous Differentially-Private Learning,” Submitted.
Collaborators: Dali Kaafar, David Smith
Funding: Next Generation Technologies Fund from the Defence Science and Technology Group (DSTG)
